Motivation
TL;DR version: This post walks through an image classification problem hosted on Kaggle for Yelp. I use Scala, DeepLearning4J and convolutional neural networks. For a self-guided tour, check out the project on Github here.
Why…
This project was motivated by a personal desire of mine to:
- explore deep learning on a computer vision problem.
- implement an end-to-end data science project in Scala.
- build an image processing pipeline using real images.
Rather than using the MNIST or CIFAR datasets with pre-processed and standardized images, I wanted to go with a more “wild” dataset of “real-world” images.
I opted for the Kaggle Yelp Restaurant Photo Classification problem. The ~200,000 training images are raw uploads from Yelp users from mobile devices or cameras with a variety of sizes, dimensions, colors and quality.
What I did instead…
I was initially going to document this project end-to-end from image processing to training the convolutional neural networks. However, upon more research and practice actually tuning convolutional networks, I’ve reconsidered my process. While the Kaggle Yelp Photo Classification problem is a novel problem, it turns out not to be a great match with the deep learning techniques I wanted to explore. Thus, this article will focus mainly on the image processing pipeline using Scala. While I introduce DL4J here, I plan to discuss my experience with it in more detail in a forthcoming post.
The Kaggle problem
The Kaggle problem is this. Yelp wants to auto-classify restaurants on the 9 characteristics below:
- good_for_lunch
- good_for_dinner
- takes_reservations
- outdoor_seating
- restaurant_is_expensive
- has_alcohol
- has_table_service
- ambience_is_classy
- good_for_kids
Each restaurant has some number of images (from a couple to several hundred). However there are no restaurant features beyond these images. Thus it is a multiple-instance learning problem where each business in the training data is represented by its bag of images.
This is also a multiple-label classification problem where each business can have one or more of the 9 characteristics listed above.
Initial approach
To deal with the multiple-instance issue, I simply applied the labels of the restaurant to all of the images associated with it and treated each image as a separate record.
To deal with with the multiple-label problem, I simply handled each class as a separate binary classification problem. While there are breeds of neural networks capable of classifying multiple labels, such as BP-MLL, these are not currently available in DL4J.
Pivot
While I didn’t expect my initial approach would land me at the top of the Kaggle leaderboard, I did expect it would allow me to build a reasonable model while exploring new and untested (to me) tools and techniques: DeepLearning4j, Scala and convolutional nets. That assumption turned out to bigger than I expected.
The noise-to-signal ratio turned out to be too high with the Yelp data to train a meaningful convolutional network given my self-imposed constraints. From what I’ve deduced from the Kaggle forum, most teams are using pre-trained neural networks to extract features from each image. From there it can be tackled as a classical (non-image) classification problem with crafty feature creation and aggregation from the image to restaurant level.
While this is far more computationally efficient and could yield better predictions, it cuts out exactly the part I wanted to explore. I eventually compromised with myself and decided to re-factor the image pipeline I developed on this project for a similar better posed problem using CIFAR or dataset created myself from using image-net.
Approach
Image processing
Images in the training set come in various shapes and sizes. See some examples below. My first pass at processing consists of:
- squaring images
- resizing image to same same dimensions
- grayscaling image
Some images are tall…


Some images are wide…


Some images are outside…


Some images are inside…


Some images are food…


And some are random other things…


1. Square images
While images in the training set varied from portrait to landscape and the number of pixels, most were roughly square. Many were exactly 500 x 375, which was also the largest size, presumably the output of Yelp’s own image processing system.
To train a convolutional net, all images need to be the same shape and size. While there are likely fancier tricks and techniques that allow for different sized images, I started simple: make all images square, while preserving as much of the image as possible. I assume that the material of interest is centered, so I capture the middle-most square of each image.
Example:

This example was created with the following code:
2. Re-size images
Now that images are squared, the re-sizing problem is relatively straightforward.
Example:




This example was created with the following code:
3. Grayscale
While DL4J and convolutional nets can certainly handle color images, I decided to simplify computation and start with grayscale. This way a single 64 x 64 pixel image is represented by 4096 features rather than 4096*3 (one for each color channel: R, G, B). There is a good discussion of the numerous ways to do this here. I opted to start with the simplest of all (averaging) which appeared to work quite well. Here’s an example:

This example was created with the following code:
Pipeline - images
Much of this section is specific to the Kaggle problem and discusses the data structures I created and used to keep store and manage images with their corresponding labels. It’s mainly an exploration of how to structure a data science project with Scala. If you’re primarily interested in DL4J, skip ahead to the Pipeline - DL4J section.
Image processing
In my image processing pipeline, I modified the functions in the Gists above to methods of the java.awt.image.BufferedImage class.
This allows me to operate on images with chaining like this:
import imgUtils._
val img = ImageIO.read(new File("myimagefile.jpg"))
.makeSquare
.resizeImg(128, 128)
.image2grayI’m not sure if this approach of extending an existing class with new methods is preferred to creating a new class, but it seemed to work well for my problem. I imagine it would be less clean if all instances of the original class do not need the newly defined methods. However, this wasn’t the case for me: all images need the new methods.
Code below: extendBufferedImage.scala
package modeling.processing
import scala.Vector
import org.imgscalr._
object imgUtils {
implicit class extendingImageClass(img: java.awt.image.BufferedImage) {
// image 2 vector processing
def pixels2gray(red: Int, green:Int, blue: Int): Int = (red + green + blue) / 3
def pixels2color(red: Int, green:Int, blue: Int): Vector[Int] = Vector(red, green, blue)
private def image2vec[A](f: (Int, Int, Int) => A ): Vector[A] = {
val w = img.getWidth
val h = img.getHeight
for { w1 <- (0 until w).toVector
h1 <- (0 until h).toVector
} yield {
val col = img.getRGB(w1, h1)
val red = (col & 0xff0000) / 65536
val green = (col & 0xff00) / 256
val blue = (col & 0xff)
f(red, green, blue)
}
}
def image2gray: Vector[Int] = image2vec(pixels2gray)
def image2color: Vector[Int] = image2vec(pixels2color).flatten
// make image square
def makeSquare = {
val w = img.getWidth
val h = img.getHeight
val dim = List(w, h).min
img match {
case x if w == h => img
case x if w > h => Scalr.crop(img, (w-h)/2, 0, dim, dim)
case x if w < h => Scalr.crop(img, 0, (h-w)/2, dim, dim)
}
}
// resize pixels
def resizeImg(width: Int, height: Int) = {
Scalr.resize(img, Scalr.Method.BALANCED, width, height)
}
}
}I/O
We need to load a couple CSV files containing metadata about each image. There are some Scala CSV reader libraries out there like scala-csv, however I forwent these to get more experience testing out Scala. I defined a basic file-reader readcsv which is used by readBizLabels and readBiz2ImgLabels to read in text files containing the labels for each Yelp business and image-to-business mappings respectively.
Code below: readCsvData.scala
package modeling.io
import scala.io.Source
object readCsvData {
/** Generic function to load in CSV */
def readcsv(csv: String, rows: List[Int]=List(-1)): List[List[String]] = {
val src = Source.fromFile(csv)
def reading(csv: String): List[List[String]] = {
src.getLines.map(x => x.split(",").toList)
.toList
}
try {
if(rows==List(-1)) reading(csv)
else rows.map(reading(csv))
} finally {
src.close
}
}
/** Create map from bizid to labels of form bizid -> Set(labels) */
def readBizLabels(csv: String, rows: List[Int]=List(-1)): Map[String, Set[Int]] = {
val src = readcsv(csv)
src.drop(1) // drop header
.map(x => x match {
case x :: Nil => (x(0).toString, Set[Int]())
case _ => (x(0).toString, x(1).split(" ").map(y => y.toInt).toSet)
}).toMap
}
/** Create map from imgID to bizID of form imgID -> busID */
def readBiz2ImgLabels(csv: String, rows: List[Int] = List(-1)): Map[Int, String] = {
val src = readcsv(csv)
src.drop(1) // drop header
.map(x => x match {
case x :: Nil => (x(0).toInt, "-1")
case _ => (x(0).toInt, x(1).split(" ").head)
}).toMap
}Wrangling
I make heavy use of the Scala map class. Essentially we have three maps:
- bizMap (imgID -> bizID)
- dataMap (imgID -> img data)
- labMap (bizID -> labels)
I suppose I could have made classes for each of these as well, but they’re really just intermediate data structures, so I didn’t bother.
readBizLabels from the code above creates the bizMap and readBiz2ImgLabels creates the imgMap. processImages from the code below creates the dataMap. Next step: create a single data representation of these three separate but related data structures.
Code below: images.scala
package modeling.processing
import java.io.File
import javax.imageio.ImageIO
import scala.util.matching.Regex
import imgUtils._
object images {
/** Define RegEx to extract jpg name from the image class which is used to match against training labels */
val patt_get_jpg_name = new Regex("[0-9]")
/** Collects all images associated with a BizId. */
def getImgIdsForBizId(bizMap: Map[Int, String], bizIds: List[String]): List[Int] = {
bizMap.filter(x => bizIds.exists(y => y == x._2)).map(_._1).toList
}
/** Get a list of images to load and process
*
* @param photoDir directory where the raw images reside
* @param ids optional parameter to subset the images loaded from photoDir.
*
* @example println(getImageIds("/Users/abrooks/Documents/kaggle_yelp_photo/train_photos/", ids=List.range(0,10)))
*/
def getImageIds(photoDir: String, bizMap: Map[Int, String] = Map(-1 -> "-1"), bizIds: List[String] = List("-1")): List[String] = {
val d = new File(photoDir) // new File("data/images/") // too many photos?
val imgsPath = d.listFiles().map(x => x.toString).toList
if (bizMap == Map(-1 -> "-1") || bizIds == List(-1)) {
imgsPath
} else {
val imgsMap = imgsPath.map(x => patt_get_jpg_name.findAllIn(x).mkString.toInt -> x).toMap
val imgsPathSub = getImgIdsForBizId(bizMap, bizIds)
imgsPathSub.map(x => imgsMap(x))
}
}
/** Read and process images into a photoID -> vector map
*
* @param imgs list of images to read-in. created from getImageIds function.
* @param resizeImgDim dimension to rescale square images to
* @param nPixels number of pixels to maintain. mainly used to sample image to drastically reduce runtime while testing features.
*
* @example
val imgs = getImageIds("/Users/abrooks/Documents/kaggle_yelp_photo/train_photos/", ids=List(0,1,2,3,4))
println(processImages(imgs, resizeImgDim = 128, nPixels = 16)) */
def processImages(imgs: List[String], resizeImgDim: Int = 128, nPixels: Int = -1): Map[Int, Vector[Int]] = {
imgs.map(x =>
patt_get_jpg_name.findAllIn(x).mkString.toInt -> {
val img0 = ImageIO.read(new File(x))
.makeSquare
.resizeImg(resizeImgDim, resizeImgDim) // (200, 200)
.image2gray
if(nPixels != -1) img0.slice(0, nPixels)
else img0
}
).filter( x => x._2 != ())
.toMap
}Data structure
So there are four pieces of information to keep track of for each image:
- imageID
- bizID
- labels
- pixel data
The data is represented like this:
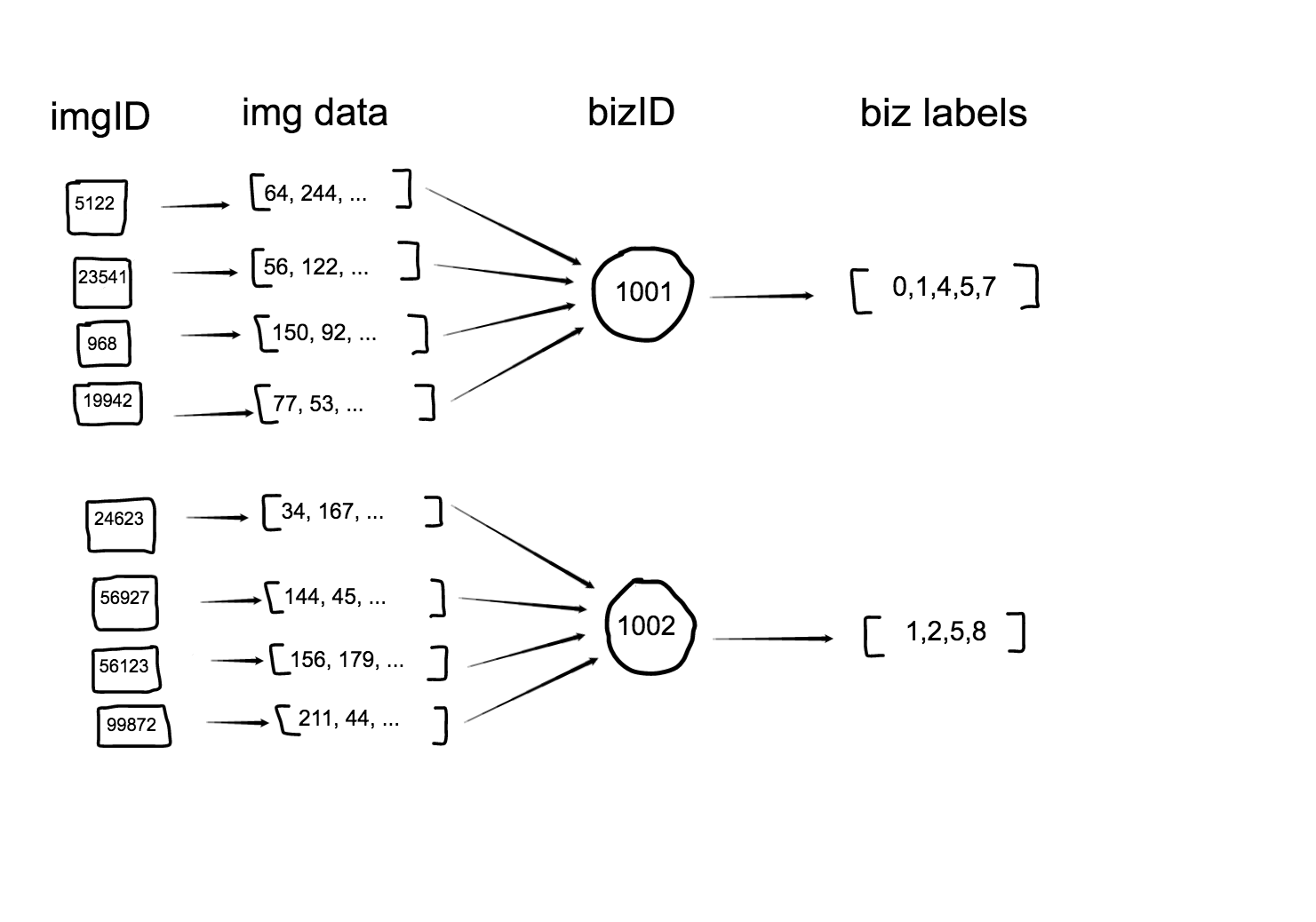
I defined a class alignedData to manage it all. When instantiating an instance of alignedData, the bizMap, dataMap and labMap are provided. I used Scala’s Option type for labMap since we don’t have this information when we score test data. None is provided that case.
Under the hood, the primary data structure has the following type:
List[(Int, String, Vector[Int], Set[Int])]
which corresponds to a list of Tuple4s containing this information:
List[(imgID, bizID, pixel data vector, labels)]
Code below: alignedData.scala
package modeling.processing
class alignedData(dataMap: Map[Int, Vector[Int]], bizMap: Map[Int, String], labMap: Option[Map[String, Set[Int]]])
(rowindices: List[Int] = dataMap.keySet.toList) {
// initializing alignedData with empty labMap when it is not provided (we are working with training data)
def this(dataMap: Map[Int, Vector[Int]], bizMap: Map[Int, String])(rowindices: List[Int]) = this(dataMap, bizMap, None)(rowindices)
def alignBizImgIds(dataMap: Map[Int, Vector[Int]], bizMap: Map[Int, String])
(rowindices: List[Int] = dataMap.keySet.toList): List[(Int, String, Vector[Int])] = {
for { pid <- rowindices
val imgHasBiz = bizMap.get(pid) // returns None if img does not have a bizID
val bid = if(imgHasBiz != None) imgHasBiz.get else "-1"
if (dataMap.keys.toSet.contains(pid) && imgHasBiz != None)
} yield {
(pid, bid, dataMap(pid))
}
}
def alignLabels(dataMap: Map[Int, Vector[Int]], bizMap: Map[Int, String], labMap: Option[Map[String, Set[Int]]])
(rowindices: List[Int] = dataMap.keySet.toList): List[(Int, String, Vector[Int], Set[Int])] = {
def flatten1[A, B, C, D](t: ((A, B, C), D)): (A, B, C, D) = (t._1._1, t._1._2, t._1._3, t._2)
val al = alignBizImgIds(dataMap, bizMap)(rowindices)
for { p <- al
} yield {
val bid = p._2
val labs = labMap match {
case None => Set[Int]()
case x => (if(x.get.keySet.contains(bid)) x.get(bid) else Set[Int]())
}
flatten1(p, labs)
}
}
// pre-computing and saving data as a val so method does not need to re-compute each time it is called.
lazy val data = alignLabels(dataMap, bizMap, labMap)(rowindices)
// getter functions
def getImgIds = data.map(_._1)
def getBizIds = data.map(_._2)
def getImgVectors = data.map(_._3)
def getBizLabels = data.map(_._4)
def getImgCntsPerBiz = getBizIds.groupBy(identity).mapValues(x => x.size)
}Make ND4J dataset
Last step is to create the data structure that DL4J needs for training convolutional nets. That data structure is an ND4J DataSet.
This is relatively straightforward once you figure out how to convert native Scala data structures to this type.
Code below: makeDataSets.scala
package modeling.processing
import org.nd4j.linalg.dataset.{DataSet}
import org.nd4s.Implicits._
import org.nd4j.linalg.api.ndarray.INDArray
import alignedData._
object makeDataSets {
/** Creates DataSet object from the data structure of data structure from alignLables function in form List[(imgID, bizID, labels, pixelVector)] */
def makeDataSet(alignedData: alignedData, bizClass: Int): DataSet = {
val alignedXData = alignedData.getImgVectors.toNDArray
val alignedLabs = alignedData.getBizLabels.map(x => if (x.contains(bizClass)) Vector(1, 0) else Vector(0, 1)).toNDArray
new DataSet(alignedXData, alignedLabs)
}
def makeDataSetTE(alignedData: alignedData): INDArray = {
alignedData.getImgVectors.toNDArray
}
}Run
The code to actually run the image processing pipeline boils down to the following:
Code below: snippet from main.scala
import io.readCsvData._
import processing.alignedData
import processing.images._
import processing.makeDataSets._
object runPipeline {
def main(args: Array[String]): Unit = {
// image processing on training data
val labMap = readBizLabels("data/labels/train.csv")
val bizMap = readBiz2ImgLabels("data/labels/train_photo_to_biz_ids.csv")
val imgs = getImageIds("data/images/train", bizMap, bizMap.map(_._2).toSet.toList)
val dataMap = processImages(imgs, resizeImgDim = 64)
val alignedData = new alignedData(dataMap, bizMap, Option(labMap))()Pipeline - DL4J
I didn’t find many examples of DL4J applications in Scala… one of the reasons I’m documenting this project in detail. However, there are some useful examples here.
Batch-mode
This took some exploring to figure out. The default speficification for DL4J networks that run with the ND4J DataSet do not train in batches. That is, each epoch (full pass through the training examples) will train on all training examples in one computation step. So all images, their data and corresponding weights must be held in memory at once.
This hogs memory with all but the smallest of datasets. I was running into heap space errors with just ~2,000 images sized 128 x 128. After switching to batch-mode, I was able to train on tens of thousands of images without memory issues.
Before I discovered this was the cause of my heap space problem, I posed my problem to the project contributors on the DL4J Gitter. I was pleased to learned that the next release of DL4J (3.9) is planned to move some computational operations off heap.
How to use batches
It’s easier to figure this out now that the DL4J examples repo has a convolutional net example (MNIST) using batches, which as of a few weeks ago was not there.
The biggest difference from mini-batch to full-batch mode is that you need to pass a MultipleEpochsIterator object rather than a ND4J DataSet to the fit method of your MultiLayerNetwork object. My approach doesn’t fully embrace iterators for their intended purpose, but hey it works and made for a smooth transition using my pipeline. You also need to add .miniBatch(true) to your MultiLayerConfiguration.Builder.
The distinction between iterations and epochs can be slightly confusing when moving from full-batch to mini-batch mode. If you’re not using miniBatches, the iterations method is used to specify how many epochs you want. However, when using batches, this is done directly in MultipleEpochsIterator and iterations can be set to 1. Explained here in the DL4J documentation.
import org.deeplearning4j.datasets.iterator.MultipleEpochsIterator
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator
val nbatches = 128
val nepochs = 100
val dsiterTr = new ListDataSetIterator(trainTest.getTrain.asList(), nbatch)
val dsiterTe = new ListDataSetIterator(trainTest.getTest.asList(), nbatch)
val epochitTr: MultipleEpochsIterator = new MultipleEpochsIterator(nepochs, dsiterTr)
val epochitTe: MultipleEpochsIterator = new MultipleEpochsIterator(nepochs, dsiterTe)Train convolutional network
This is the function that actually trains the convolutional net. It’s is long, probably too long. Lots of hyper-parameters hardcoded within that could be moved to function arguments or better yet, a config file. However, I was running locally on laptop with lots of tinkering, so this worked fine for me.
The CNN training function below does a lot: logging, test/train splitting, creating the MultipleEpochsIterator, training, reporting performance on test data, and saving the trained models to file.
I’ll save the intuition behind tuning for another post after I gain a better understanding myself on a more well posed problem. For now I’ll just ramble about what I tried and what happened.
Layers: I observed from some papers benchmarking convolutional nets solving the MNIST problem that a single convolutional layer generates decent results (certainly better than a benchmark of random, at least enough get started with). I trained with runs with up to three convolutional layers without errors, but my training was obviously slower (although not exponentially) and results were not any better than with one layer. Next time I plan to start with one convolutional layer, start tuning other parameters to get above benchmark results… and then explore additional layers.
# of samples: Training on all images took so much time, I didn’t have the patience to let it finish. It took me about 2 days to run a watered down CNN on my laptop with 50,000 images.
nepochs: This is the number of passes through all the training records. I’ve seen some networks with as few as 20 to as many as 1000 epochs. This is the main idea. There’s also an in-depth discussion about this here. I spent most of my tuning time trading off nepochs and the # of samples. I could tolerate training with lots of images to expose the network to a broader universe of features to learn… but only by cutting down the number of epochs to make run-time manageable.
nOut: This is the number feature maps. I tried runs with 10 to 500, chosen mostly by reviewing configurations for other image problems and the example DL4J networks.
learningRate: From what I’ve read this is pretty important. I didn’t fiddle with this much though. I think I tried the commonly used .01 and .001.
nbatch: This is the # of records in each batch. I tried 32, 64 and 128. I’m not sure how much of a difference this makes for results vs. computation.
Code below: cnnEpochs.scala. A simpler version using full-batch training is here.
package modeling.training
import modeling.processing.makeDataSets._
import modeling.io._
import modeling.processing.alignedData
import java.util.Random
import java.nio.file._
import java.io.{DataOutputStream, File}
import org.apache.commons.io.FileUtils
import org.deeplearning4j.eval.Evaluation
import org.deeplearning4j.nn.api.OptimizationAlgorithm
import org.deeplearning4j.nn.conf.layers.setup.ConvolutionLayerSetup
import org.deeplearning4j.nn.conf.layers.{ConvolutionLayer, OutputLayer, SubsamplingLayer, DenseLayer}
import org.deeplearning4j.nn.conf.{MultiLayerConfiguration, NeuralNetConfiguration}
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork
import org.deeplearning4j.nn.weights.WeightInit
import org.deeplearning4j.optimize.api.IterationListener
import org.deeplearning4j.optimize.listeners.ScoreIterationListener
import org.nd4j.linalg.api.ndarray.INDArray
import org.nd4j.linalg.dataset.SplitTestAndTrain
import org.nd4j.linalg.factory.Nd4j
import org.nd4j.linalg.lossfunctions.LossFunctions
import org.slf4j.LoggerFactory
import scala.collection.JavaConverters._
import org.deeplearning4j.datasets.iterator.MultipleEpochsIterator
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator
object cnnEpochs {
def trainModelEpochs(alignedData: alignedData, bizClass: Int = 1, saveNN: String = "") = {
val ds = makeDataSet(alignedData, bizClass)
println("commence training!!")
println("class for training: " + bizClass)
val begintime = System.currentTimeMillis()
lazy val log = LoggerFactory.getLogger(cnn.getClass)
log.info("Begin time: " + java.util.Calendar.getInstance().getTime())
val nfeatures = ds.getFeatures.getRow(0).length // hyper, hyper parameter
val numRows = Math.sqrt(nfeatures).toInt // numRows * numColumns must equal columns in initial data * channels
val numColumns = Math.sqrt(nfeatures).toInt // numRows * numColumns must equal columns in initial data * channels
val nChannels = 1 // would be 3 if color image w R,G,B
val outputNum = 2 // # of classes (# of columns in output)
val iterations = 1
val splitTrainNum = math.ceil(ds.numExamples*0.8).toInt // 80/20 training/test split
val seed = 123
val listenerFreq = 1
val nepochs = 20
val nbatch = 128 // recommended between 16 and 128
//val nOutPar = 500 // default was 1000. # of output nodes in first layer
println("rows: " + ds.getFeatures.size(0))
println("columns: " + ds.getFeatures.size(1))
/**
*Set a neural network configuration with multiple layers
*/
log.info("Load data....")
ds.normalizeZeroMeanZeroUnitVariance() // this changes ds
System.out.println("Loaded " + ds.labelCounts)
Nd4j.shuffle(ds.getFeatureMatrix, new Random(seed), 1) // this changes ds. Shuffles rows
Nd4j.shuffle(ds.getLabels, new Random(seed), 1) // this changes ds. Shuffles labels accordingly
val trainTest: SplitTestAndTrain = ds.splitTestAndTrain(splitTrainNum, new Random(seed)) // Random Seed not needed here
// creating epoch dataset iterator
val dsiterTr = new ListDataSetIterator(trainTest.getTrain.asList(), nbatch)
val dsiterTe = new ListDataSetIterator(trainTest.getTest.asList(), nbatch)
val epochitTr: MultipleEpochsIterator = new MultipleEpochsIterator(nepochs, dsiterTr)
val epochitTe: MultipleEpochsIterator = new MultipleEpochsIterator(nepochs, dsiterTe)
val builder: MultiLayerConfiguration.Builder = new NeuralNetConfiguration.Builder()
.seed(seed)
.iterations(iterations)
.miniBatch(true)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.learningRate(0.01)
.momentum(0.9)
.list(4)
.layer(0, new ConvolutionLayer.Builder(6,6)
.nIn(nChannels)
.stride(2,2) // default stride(2,2)
.nOut(20) // # of feature maps
.dropOut(0.5)
.activation("relu") // rectified linear units
.weightInit(WeightInit.RELU)
.build())
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX, Array(2,2))
.build())
.layer(2, new DenseLayer.Builder()
.nOut(40)
.activation("relu")
.build())
.layer(3, new OutputLayer.Builder(LossFunctions.LossFunction.MCXENT)
.nOut(outputNum)
.weightInit(WeightInit.XAVIER)
.activation("softmax")
.build())
.backprop(true).pretrain(false)
new ConvolutionLayerSetup(builder, numRows, numColumns, nChannels)
val conf: MultiLayerConfiguration = builder.build()
log.info("Build model....")
val model: MultiLayerNetwork = new MultiLayerNetwork(conf)
model.init()
model.setListeners(Seq[IterationListener](new ScoreIterationListener(listenerFreq)).asJava)
log.info("Train model....")
System.out.println("Training on " + dsiterTr.getLabels) // this might return null
model.fit(epochitTr)
// TRAINING
log.info("Evaluate model....")
System.out.println("Testing on ...")
val eval = new Evaluation(outputNum)
while(epochitTe.hasNext) {
val testDS = epochitTe.next(nbatch)
val output: INDArray = model.output(testDS.getFeatureMatrix)
eval.eval(testDS.getLabels(), output)
}
System.out.println(eval.stats())
val endtime = System.currentTimeMillis()
log.info("End time: " + java.util.Calendar.getInstance().getTime())
log.info("computation time: " + (endtime-begintime)/1000.0 + " seconds")
log.info("Write results....")
if(!saveNN.isEmpty) {
// model config
FileUtils.write(new File(saveNN + ".json"), model.getLayerWiseConfigurations().toJson())
// model parameters
val dos: DataOutputStream = new DataOutputStream(Files.newOutputStream(Paths.get(saveNN + ".bin")))
Nd4j.write(model.params(), dos)
}
log.info("****************Example finished********************")
}
}Save/load networks
This is definitely something you’ll want to do. These things take too long to train to not save immediately.
saveNN is pretty straightforward. It saves a .json file with the network configuration and a .bin with all the weights and parameters of the network you just trained.
loadNN just reads back the .json and .bin file you created with saveNN to a MultiLayerNetwork object that you can use to score new test data.
Code below: nn.scala
package modeling.io
import org.deeplearning4j.nn.conf.{GradientNormalization, MultiLayerConfiguration, NeuralNetConfiguration}
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork
import org.nd4j.linalg.factory.Nd4j
import java.io.File
import org.apache.commons.io.FileUtils
import java.io.{DataInputStream, DataOutputStream, FileInputStream}
import java.nio.file.{Files, Paths}
object nn {
def loadNN(NNconfig: String, NNparams: String) = {
// get neural network config
val confFromJson: MultiLayerConfiguration = MultiLayerConfiguration.fromJson(FileUtils.readFileToString(new File(NNconfig)))
// get neural network parameters
val dis: DataInputStream = new DataInputStream(new FileInputStream(NNparams))
val newParams = Nd4j.read(dis)
// creating network object
val savedNetwork: MultiLayerNetwork = new MultiLayerNetwork(confFromJson)
savedNetwork.init()
savedNetwork.setParameters(newParams)
savedNetwork
}
def saveNN(model: MultiLayerNetwork, NNconfig: String, NNparams: String) = {
// save neural network config
FileUtils.write(new File(NNconfig), model.getLayerWiseConfigurations().toJson())
// save neural network parms
val dos: DataOutputStream = new DataOutputStream(Files.newOutputStream(Paths.get(NNparams)))
Nd4j.write(model.params(), dos)
}
}Scoring
I won’t say much here, since I didn’t end up putting much emphasis on this step for reasons explained at the beginning of this post.
My scoring approach assigns business-level labels by averaging the image-level predictions. I classify a business as label “0” if the average of the probabilities across all of its images belonging class “0” is greater than 0.5.
Code below: scoring.scala
package modeling.processing
import org.nd4j.linalg.api.ndarray.INDArray
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork
object scoring {
def scoreModel(model: MultiLayerNetwork, ds: INDArray) = {
model.output(ds)
}
/** Take model predictions from scoreModel and merge with alignedData*/
def aggImgScores2Biz(scores: INDArray, alignedData: alignedData ) = {
assert(scores.size(0) == alignedData.data.length, "alignedData and scores length are different. They must be equal")
def getRowIndices4Biz(mylist: List[String], mybiz: String): List[Int] = mylist.zipWithIndex.filter(x => x._1 == mybiz).map(_._2)
def mean(xs: List[Double]) = xs.sum / xs.size
alignedData.getBizIds.distinct.map(x => (x, {
val irows = getRowIndices4Biz(alignedData.getBizIds, x)
val ret = for(row <- irows) yield scores.getRow(row).getColumn(1).toString.toDouble
mean(ret)
}))
}
}Submit to Kaggle
Also not much to say here, but this is how I aggregated image predictions to business scores for each model. And this is the code to generate the output CSV for Kaggle.
Run
The whole project can be run from main.scala. Here it is:
package modeling
import io.nn._
import io.kaggleSubmission._
import io.readCsvData._
import processing.alignedData
import processing.images._
import processing.kaggleSubmission._
import processing.makeDataSets._
import processing.scoring._
import training.cnn._
import training.cnnEpochs._
object runPipeline {
def main(args: Array[String]): Unit = {
// image processing on training data
val labMap = readBizLabels("data/labels/train.csv")
val bizMap = readBiz2ImgLabels("data/labels/train_photo_to_biz_ids.csv")
val imgs = getImageIds("data/images/train", bizMap, bizMap.map(_._2).toSet.toList).slice(0,20000) // 20000 images
val dataMap = processImages(imgs, resizeImgDim = 128)
val alignedData = new alignedData(dataMap, bizMap, Option(labMap))()
// training (one model/class at a time). Many microparameters hardcoded within
val cnn0 = trainModelEpochs(alignedData, bizClass = 0, saveNN = "results/modelsV0/model0")
val cnn1 = trainModelEpochs(alignedData, bizClass = 1, saveNN = "results/modelsV0/model1")
val cnn2 = trainModelEpochs(alignedData, bizClass = 2, saveNN = "results/modelsV0/model2")
val cnn3 = trainModelEpochs(alignedData, bizClass = 3, saveNN = "results/modelsV0/model3")
val cnn4 = trainModelEpochs(alignedData, bizClass = 4, saveNN = "results/modelsV0/model4")
val cnn5 = trainModelEpochs(alignedData, bizClass = 5, saveNN = "results/modelsV0/model5")
val cnn6 = trainModelEpochs(alignedData, bizClass = 6, saveNN = "results/modelsV0/model6")
val cnn7 = trainModelEpochs(alignedData, bizClass = 7, saveNN = "results/modelsV0/model7")
val cnn8 = trainModelEpochs(alignedData, bizClass = 8, saveNN = "results/modelsV0/model8")
// processing test data for scoring
val bizMapTE = readBiz2ImgLabels("data/labels/test_photo_to_biz.csv")
val imgsTE = getImageIds("data/images/test/", bizMapTE, bizMapTE.map(_._2).toSet.toList)
val dataMapTE = processImages(imgsTE, resizeImgDim = 128)
val alignedDataTE = new alignedData(dataMapTE, bizMapTE, None)()
// creating csv file to submit to kaggle (scores all models)
val kaggleResults = createKaggleSubmitObj(alignedDataTE, "results/ModelsV0/")
val kaggleSubmitResults = writeKaggleSubmissionFile("results/kaggleSubmission/kaggleSubmitFile.csv", kaggleResults, thresh = 0.5)Thoughts
This was my first foray into deep neural networks. I haven’t used theano or any of the other widely used implementations out there, so I unfortunately don’t have much to compare my experience to.
I will say that the current documentation will only take you so far. I spent a lot of time reading Neural Networks and Deep Learning to understand the concepts and reviewing the DL4J source code to try and figure out how to implement what I thought I wanted to do.
Discovering the DL4J Gitter was the single most useful moment I had. The creators are actively answering all sorts of questions in real-time. There’s also a room for earlyadopters discussing testing and feature requests which was interesting to browse. Very impressed with the commitment and willingness to help. I even got an email from someone on the DL4J team after I pushed this project to GitHub offering to help and pointing me to the CNN specialists.
Gitter is where the action is. There’s way more here than on StackOverflow. However, the content doesn’t appear to be indexed nearly as well on Google, so found myself “Googling” in the Gitter search bar for keywords and perusing through conversations to get answers.
I recommend using the deeplearning4j-ui tool if you can. I unfortunately wasn’t able to get it working, but it looks super useful for understanding how your net training is going.
Other awesome resources I found for visualizing training for CNNs are ConvNetJS and this one.